Case Studies
Building a FOSS ecosystem for statistical data processing
Statistics Netherlands
Introduction
Statistics Netherlands (CBS) has embraced the use of Free and Open Source Software for statistical production for more than a decade. A significant step in that direction was taken in 2010 when R was adopted as a strategic tool for data processing1. R is both a software tool for statistical data processing and a programming language that is extensible through R packages. These packages are typically published on the Comprehensive R Archive Network, which enforces a strict quality policy on code quality, documentation, and interoperability of packages.
Recognising the need for production systems that are built out of composable and reusable (generic) modules, researchers at CBS started to both use and contribute packages to the R ecosystem. A major part of those contributions consist of R packages in the area of statistical data cleaning and data processing 2 3.
Over time, these packages have been adopted both within Statistics Netherlands and outside. Within CBS, packages are used in the production of areas covering social and economic statistics, agriculture, international trade, education, environmental statistics, emissions, income, shipping, Short-Term-Statistics, recreation, museums, and many more. Outside statistics we have seen uptake of the packages by statistical institutes of Iceland, Denmark, Italy, Brasil, and probably many more. It is noteworthy that the US Department of Agriculture National Agricultural Statistical Service (USDA-NASS 4) is using CBS R packages to validate and clean data from large national surveys under American farmers.
The R based ecosystem
The current ecosystem (Table 1) consists of a number of packages that integrate seamlessly. Not only because there is a shared technical platform (i.e., R), but also because careful thought was put in pegging out, with formal precision, what each fundamental processing step entails. Below we describe two examples demonstrating the extensibility and power of this modular approach.
The first example concerns data validation. Until about 2024, the act of checking data against domain knowledge, in the form of validation rules, was not recognised as a separate activity. In almost any available system this was either hard-coded by users or integrated in a larger data-editing system. Creating a separate package (called validate) with the sole purpose of defining, manipulating and executing data validation rules yielded the possibility of monitoring the progress of data quality along multiple statistical value chains using a single piece of software 5 6. Moreover, the rule management system of the package is reused in packages for error localisation (errorlocate), data correction (deductive) and aggregating based on dynamically defined data groupings (accumulate) 7 8 9.
A second example is an imputation package (simputation) that allows users to combine (i.e., chain) a large number of popular imputation models in fall-through scenarios that are often used in economic statistics 10. The package allows for group-wise processing, where groups are statically defined. When the need arose to extend the functionality, it was possible to define a new add-on package (accumulate) that allows for grouping of data where the grouping is determined dynamically and depending on data circumstances. The fact that it was possible to add new, unanticipated functionality is a consequence of the careful design and separation of concerns when designing each individual module.
| Table 1. R-based open source ecosystem for statistical data processing | |
|---|---|
| R package | Description |
| validate | Check validity of data based on user-defined rules. |
| dcmodify | Adapt erroneous data based on user-defined rules. |
| errorlocate | Find the minimal number of erroneous data points. |
| simputation | Many different imputation methods with a single easy to learn interface. |
| rspa | Adjust numerical records to fit equality and inequality restrictions. |
| deductive | Solve data errors, using the data and validation rules. |
| validatetools | Find contradictions and redundancies in rule sets. |
| accumulate | Grouped aggregation, where grouping is dynamic and data-dependent. |
| lumberjack | Automatically track changes in data for logging purposes 11 12. |
| reclin2 | Join datasets based on (multiple) possibly inexact keys 13. |
All packages have been developed in the open, by hosting the code on open version control repositories (i.e., GitHub), presenting the work at conferences, publishing in scientific journals, and promoting usage and feedback from (potential) users. The uptake of packages by non-CBS users is facilitated by releasing the packages on a standardised release platform (i.e., CRAN), using permissive licences and paying attention to documentation. Feedback and contributions from users outside of Statistics Netherlands, and even from outside of the official statistics community, has substantially helped improve and generalise the software. The fact that software can be easily downloaded and installed makes it trivial for R users to give the software a try and the open development platforms facilitate reporting of questions, issues, or even contributing. It should in this respect be mentioned that contributions may range from things as simple as fixing typing errors in the documentation, to demonstrating new use cases, filing bug reports, or even fixing bugs or adding functionality.
How working in FOSS contributes to the success of the ecosystem
The fact that the whole ecosystem has been developed in the open, as an open source project, has contributed crucially to the success on several levels.
In the first place there is a large FOSS community in R that provides help, a packaging system, and also an infrastructure for developing, testing, documenting and publishing packages. The fact that this infrastructure, including the presence of a global informal and helpful community, exists has been extremely helpful during design and development of the packages. The usefulness of being able to directly contact the people who develop the infrastructure one is using is hard to overstate.
Secondly, publishing the packages in open source immediately gives a large audience the opportunity to try the product: given enough eyeballs, all bugs are shallow 14. Enthusiastic users are able to contribute new use cases, issues, and documentation, which overall has contributed to creating more general and more robust software.
Adoption of OSS and governance efforts in Istat
Italian National Institute of Statistics (Istat)
Introduction
Outside of statistical software, Istat has a long experience of using open source software and already in 2004 an official working group on the use of open source software was formed. The group, made up of statistical and IT experts, studied the current uses of OS software and its potential developments. Under the impetus of the group, open source software spread throughout Istat, from Linux servers to connectivity software and various modules to support group work.
As for the statistical software, in the past Istat’s statistical work was carried out exclusively with SAS software, but for specific tasks some additional SAS tools had to be developed (e.g., MAUSS for deciding the optimal sample size and its allocation in multi-purpose surveys; GENESEES for weight calibration and estimation in sample surveys). For data processing and imputation, it was decided to use the SAS-based commercial tool BANFF, developed by Statistics Canada. Obviously, it was difficult to disseminate SAS-based tools to the members of the Italian National Statistical System (NSS) because, in most cases, they did not use SAS.
The introduction of R took place shortly after the year 2000, mainly in the Methodology Directorate, to test new methods; initially an informal group of R experts was created and met once a month; this group started to give workshops and occasional internal training (regular training started in 2007). These activities led to the identification of R as the preferred environment for developing new packages, also to replace tools developed in SAS or as stand-alone applications; the decision was also taken in response to a ministerial directive in April 2003, inviting government agencies to adopt open source software tools and avoid dependence on a single commercial software tool.
The first R packages were released around 2010 (ReGenesees for weights calibration and estimation; SamplingStrata for stratification and optimum allocation; SeleMix for selective editing; StatMatch for statistical matching), others followed later (e.g. FS4 for stratification, R2BEAT for determining optimal sample size and its allocation). In other cases, such as the RELAIS record linkage system, R became the engine for statistical computations. These packages were developed in the Methodology Directorate, and to facilitate their dissemination within the NSS and also externally, it was decided to create a repository on the corporate website 15. Packages to be included in the repository had to pass a rigorous approval procedure, which required the availability of clear documentation, a presentation to a committee and also the adoption of an EUPL licence, as recommended by the Istat Legal Office. Later, the licence requirements were relaxed and the GPL licence was also accepted, being the most popular in the R community. Some of the R packages are also distributed on CRAN and are easily accessible in the “Official Statistics” task view 16.
Today, the activities related to R are focused on the maintenance of existing packages, which have recently experienced some disruptions due to the retirement of their developers/maintainers, and on the testing of already existing external packages (instead of developing new ones). For example, Istat is testing the R packages for data editing and imputation (validate, validatetools, errorlocate, simputation 17 and VIM) with the aim of adopting them to replace our obsolete standalone tool CONCORDJava. Similar tests are underway for disclosure control (R packages ptable and cellKey). Finally, we are working on extending the functionality of the R package RJDemetra, which provides the R interface to JDemetra+, the officially recommended seasonal adjustment software within the European Statistical System.
R training for staff is provided regularly by in-house trainers; there are two “core” courses (“Base R” and “Intermediate R”) offered twice a year, and a number of short courses on specific topics/packages (e.g., the ggplot2 package) offered once a year. In addition, R tools are used in statistical courses (sampling, data integration, data processing and imputation, etc.) to demonstrate the application of methods. More generally, the developed packages and their improvements are promoted through presentations and tutorials at conferences/workshops, including the uRos 18 annual conference.
Recently, research aimed at investigating the potential use of statistical learning and more generally machine learning techniques for official statistics, also with the aim of exploiting alternative data sources such as big data, led to the adoption of Python. As with R, the approach is bottom-up, as Python is mainly used in the Methodological Directorate. Python is currently being used to produce some experimental statistics: the Social Mood on Economy Index (SMEI) and the imporT ExpoRt networK Analysis (TERRA), a tool for exploratory analysis of Eurostat data on international trade. Other ongoing projects are quite diverse: web mining to integrate and validate information from the Statistical Business Register; estimation of road accidents using big data; estimation of urban greenery using remote sensing images; imputation of education levels in the Register of Persons; estimation of shipping routes, etc., although it is already being used to produce some experimental statistics. A few years ago, it was decided to organise Python courses (basic and advanced) for staff, offered once a year.
Today, R and Python are the main languages used in the Methodology Directorate, but SAS remains the tool used in some technical units involved in the production of statistics. This is due to a number of factors: ageing staff in production units well trained in SAS and unwilling to lean and move to R; reduction of staff in production due to the inability to replace retired staff and consequently limited resources to ensure a complete migration from SAS to R; the fear of production managers of disrupting the publication of official statistics because of the introduction of new tools with limited support; and an absence of a structure ensuring support on R, contrary to what happens for SAS.
Governance
For these reasons, it was recently decided to increase efforts to ease the adoption of open source statistical tools in production directorates. The informal network of R experts will be expanded to include methodologists and subject matter experts with a solid knowledge of R and will become the official support structure for R from 2025 onwards. This network will also support the implementation of innovative methodologies (including the development of new packages) and the increase of training opportunities for staff. It should also contribute to the maintenance of packages already developed, also to avoid the problems recently experienced (i.e., the retirement of maintainers).
A first part of the Istat policy for the governance of the statistical open source software tools is expected to be published by the end of 2024-early 2025. It will mainly deal with statistical-methodological aspects and provide some basic indications on the IT infrastructure, as the two elements are closely linked. The second part, more focused on IT infrastructure and IT requirements, will be published later.
The first part of the governance of statistical open source software will provide Istat researchers with a set of guidelines and recommended practices for the development of new tools or the adoption (and adaptation) of existing ones; finally, it will redesign the procedures for their approval and dissemination (including guidance on licensing) and maintenance over time.
The guidelines for the development of new open source statistical software will be published in late 2024 and will include recommendations for writing R code and documenting it according to international standards to facilitate code sharing and reuse. A second level of documentation, tailored for internal purposes only, will document the use of the tools in the specific production process to facilitate modifications/adaptations to specific circumstances encountered in a subsequent replication of the process.
In the development of the code, much attention is paid to dependency issues in order to limit problems related to changes/disruptions in the maintenance of the packages on which the code depends. This issue will be even more relevant for the adoption and possible adaptation of externally developed open source statistical tools; guidance will be provided on the procedure to be followed: criteria for selection among different potential candidates; preliminary checks to be performed (availability and clarity of documentation; maturity, frequency of updates and possible bug fixes; limitations and dependencies on other tools; available support, etc.); and testing procedures of the selected tools in case studies of increasing complexity. For both developed and acquired/adapted existing tools, the governance policy will provide guidance on their endorsement, dissemination and promotion internally and externally.
Governance will also provide recommendations for user support, maintenance and updating of the approved tools over time. All defined procedures should be complemented by the identification and establishment of a set of governance bodies with clearly defined roles and responsibilities.
Building a community-driven OSS: The SIS-CC experience
Organisation for Economic Co-operation and Development (OECD)
The statistical information system collaboration community (SIS-CC) is a reference open source community for official statistics, focusing on product excellence and delivering concrete solutions to common problems through co-investment and co-innovation.
Licences
SIS-CC’s adherence to the principles of openness and collaboration is embodied in its strategic choice to use the MIT licence for its open source tools. MIT is a permissive free software licence and places minimal restrictions on the reuse of code, thereby maximising flexibility and fostering an environment where innovation can thrive.
The decision to select MIT over alternative open source licences, such as Apache 2.0, is rooted in the desire for simplicity and minimal legal complexity. While both licences are permissive and encourage open contribution, there are differences that made MIT a better choice for SIS-CC. For example, the concise language and straightforward terms avoid legal jargon, making it very accessible for users to understand and implement correctly. There are fewer restrictions on the redistribution of software compared to Apache 2.0, which requires explicit attribution and changes documentation among other stipulations. With its minimalist approach, MIT is broadly compatible with other licences, allowing for greater interoperability of code across various projects and jurisdictions. It enables easier participation from the community because contributors do not need to worry about complex licence compliance, which can be more challenging with Apache 2.0. By opting for the MIT licence, the SIS-CC reduces the barriers to entry for users and contributors, thereby encouraging widespread adoption and collaboration on the open source project.
While embracing the simplicity of MIT, SIS-CC also recognises the importance of managing contributions effectively. One mechanism for doing this is through Contributor Licence Agreements (CLAs) that clarifies the terms under which a contributor submits code or content to a project, protecting both the contributor and the organisation by ensuring that the intellectual property is appropriately managed. However, for SIS-CC, it was deemed too complex as it would add an unnecessary overhead to the contribution process, with the potential to deter casual contributors. Instead, the SIS-CC opted for a more automated and centrally controlled review and merge process whereby source code, reuse of libraries, and other components, are checked and validated for potential breaks in the licence chain. So far this has served the SIS-CC well and facilitated a number of contributions from outside of the core maintainers of the project.
Standards
The SIS-CC plays a pivotal role in driving and promoting the adoption of global open standards within the statistical community, specifically focusing on the Statistical Data and Metadata Exchange (SDMX) and the Generic Statistical Business Process Model (GSBPM). These standards are essential for streamlined and accurate data management across diverse systems and organisations. Through the adoption of these standards, the SIS-CC has enhanced the efficiency, accuracy, and comparability of statistical data through standardised practices, fundamentally altering how data is managed and exchanged globally. Adopting these standards has increased efficiency and cost-effectiveness through streamlined data processes, fostered consistency and comparability in data across various systems, enhancing overall data integrity, and facilitated collaboration within a standardised framework that has simplified data sharing and collaboration among statistical organisations. The adoption of SDMX and GSBPM has prepared organisations to meet future data challenges and integrate into the global statistical ecosystem effectively. The SIS-CC’s robust initiative to standardised statistical practices has not only enhanced operational efficiencies within member organisations but also strengthened the global statistical community’s capability to handle modern data demands, fostering a more connected and resilient statistical landscape. SDMX’s role in facilitating a seamless communication and collaboration across not just statistical teams but also IT within organisations highlights its capacity to catalyse multidisciplinary teamwork, by automating data flows and enhancing user-friendly data exploration, which lays the groundwork for an efficient data-sharing environment.
Powered by SDMX, the .Stat Suite, being the SIS-CC flagship product, has revolutionised how data is managed, processed, and disseminated from end-to-end, making it more accessible and easier for researchers and analysts to combine and connect in analytical work. The SIS-CC has already started to explore the integration of Artificial Intelligence (AI) with SDMX and the .Stat Suite which promises to unlock even more potential. As AI capabilities evolve, SDMX’s robust semantic framework can serve as a foundation for intelligent, automated data flows, and fostering innovations.
Knowledge Building
The commitment of SIS-CC to enhancing data skills and knowledge led to the establishment of the .Stat Academy. This initiative represents a comprehensive effort to democratise access to self-paced online training, with a focus on enhancing the knowledge of data practitioners in data modelling and SDMX, as well as data toolers in the technologies and tools needed to support the statistical lifecycle. Through a diverse array of free online courses and resources, the .Stat Academy is empowering data professionals worldwide. It leverages a blended learning approach of online courses, hands-on workshops, and collaborative projects to facilitate learning. This multifaceted approach ensures that participants gain practical experience alongside theoretical knowledge. By offering courses on a wide range of topics, the .Stat Academy caters to varying levels of expertise and professional needs, fostering a vibrant, global community of data practitioners who share insights, challenges, and solutions, thus collectively advancing the field of statistical information systems.
Culture
The journey from a closed community software development to an open source model represented a profound cultural shift for the SIS-CC. This evolution demanded a paradigm change, where openness, transparency, and collective engagement became the cornerstones of development. As SIS-CC members transitioned to open source practices, they embraced a culture that championed collaboration beyond organisational confines, paving the way for more innovative solutions. This shift confronted traditional viewpoints which emphasised proprietary control, urging a reorientation towards shared stewardship and a belief that pooling resources can lead to better outcomes.
Adopting an open source culture necessitated overcoming numerous challenges. Developers had to recalibrate their approaches to software development—acknowledging that the broader community can contribute valuable insights and code improvements that no single entity could achieve alone. It required rethinking strategies around intellectual property, where inclusivity in innovation assumes priority over exclusivity. The shift to DevSecOps demanded a cultural overhaul where the team worked collaboratively across the entire development cycle, breaking down traditional silos. It required nurturing a mindset that places equal emphasis on speed and security, embedding security considerations from the onset of development rather than being an afterthought. To deal with the resistance that such a profound change brings demanded a concerted effort in training, change management, and the establishment of new norms.
Governance
The SIS-CC operates within a multi-tier community ecosystem, underpinning a sustainable business model that promotes co-innovation and co-investment. This multifaceted governance structure is essential for managing the dynamics of collaboration among diverse organisations and partners. Central to its governance is the multi-tier community ecosystem, meticulously designed to foster balanced user growth while ensuring the retention of agility and the maintenance of product excellence. This structure categorises members into different tiers based on the nature and extent of their contribution. Tier 1 organisations are pivotal, providing financial and in-kind contributions. This tier has the potential for receiving additional grants, reflecting a deep investment in the community and product advancement. Tier 2 organisations benefit either through commercial avenues or through institutional backing, like that provided by the ILO LMIS 19 project. This ensures a diverse range of organisational types and resources are contributing to and benefitting from the community. Tier 3 organisations access the Community products through self-service tools, such as Gitlab, documentation, the .Stat Academy, and issue tickets, enabling broader, more accessible participation.
The governance philosophy of the SIS-CC champions an inclusive strategy, laying its foundations on the Community Foundations: Community Driven Dynamics; Open source Delivery; Full Data Lifecycle; Componentised Architecture; and Systematic User Research. These foundations are critical in a shared journey towards achieving mutual objectives, enhancing collaboration, and solidifying our collective value proposition.
Transforming a software into OSS at SORS
Statistical Office of the Republic of Serbia (SORS)
Introduction
The Statistical Office of the Republic of Serbia (SORS) has over the past 15 years developed the Istraživanje (IST) 20, a metadata driven statistical collection and production solution aligned with GSBPM, to meet the growing needs of statistical data processing in a rapidly evolving technological environment. The IST platform was developed in response to the complexity of statistical data handling, which requires a flexible, modular, and metadata-driven approach to ensure efficiency across the statistical lifecycle.
Since its launch in 2006, IST has been deployed in several NSOs, including those in Kyrgyzstan, Montenegro, Bosnia and Herzegovina, and Albania. The platform was shared through Memorandums of Understanding (MoUs) and provided to partner NSOs as free software. As part of these agreements, SORS supplied the full source code and ongoing support, further demonstrating its commitment to international cooperation and statistical innovation. Over time, IST evolved through continuous feedback from these partners, further refining its features and capabilities.
Collaborative Effort
Although IST was entirely developed by SORS, its expansion and refinement were facilitated by collaborations with other NSOs. These partnerships enabled SORS to adapt IST to different country-specific contexts while ensuring that the core system remained robust, flexible, and adaptable. The software’s success lies in support for various file formats, languages, its modular design (which allows for integration with additional tools widespread among NSOs), and its comprehensive metadata management features that guide the statistical process from data collection to dissemination.
Key Features of IST
IST is a metadata-driven system designed to ensure seamless data management throughout the statistical process. Its architecture allows for real-time data entry, validation, and processing, making it an essential tool for modern statistical operations. The key features of IST include:
- Metadata-Driven Architecture: IST leverages metadata to control data processing workflows. This design ensures consistency and efficiency across different stages of data collection, validation, and analysis.
- Modular Design: The platform’s architecture allows independent modules to be added or modified without affecting the entire system. This flexibility makes IST scalable and adaptable to various statistical requirements.
- Advanced Reporting Capabilities: IST supports real-time reporting in multiple formats, such as Excel, JSON, CSV, TXT, and XML, facilitating easy data dissemination.
Steps Toward Open Source
In recent years, SORS has recognised the importance of promoting open source solutions to foster collaboration and enhance the usability of IST across multiple regions. As part of this strategy, SORS has initiated a comprehensive plan to release IST as an open source product, adhering to widely accepted licensing and contribution practices.
IST Productisation Steps
The transition to open source requires a structured and phased approach. In collaboration with international partners and legal experts, SORS is devising the plans for making IST open source:
- Defining Governance and Contribution Models: A key aspect of the open source transition is the establishment of clear governance models based on the foundations of openness, collaboration, and sustainability. SORS aims to implement a Contributor Licence Agreement (CLA) to ensure that all contributions are legally bound to be licenced back to SORS, preserving control over the project’s direction (lead by the Project Management Committee) while encouraging community contributions.
- Technical Documentation and Support: IST’s open source version will be accompanied by comprehensive documentation, including user and developer manuals. SORS will continue to provide remote support to partner NSOs to ensure smooth implementation and adoption of the open source version.
- Licensing Strategy: Following a thorough review of different open source licences, SORS decided to use the Apache licence 2.0 with additional clauses to restrict the commercial redistribution of IST. This decision ensures that IST remains freely available for statistical offices and developers, while retaining legal protections over its intellectual property. The final decision will be made after thorough consideration by legal experts.
- Publishing and Maintenance: IST’s source code will be published on an open source platform, such as GitHub / GitLab, allowing for easy access and collaboration. The platform will also serve as a space for tracking issues, managing contributions, and providing updates.
Licences
Two open source licences were considered for IST’s transition to open source: the MIT licence and the Apache licence 2.0. After careful evaluation, SORS opted for the Apache licence 2.0, which offers both permissive use and patent protection. This licence allows IST to be widely adopted while safeguarding SORS’s intellectual property rights.
Key factors influencing this decision include:
- Patent Protection: Apache 2.0 includes an explicit patent grant, offering legal protection against patent-related disputes.
- Broad Usage and Modification Rights: The licence allows other statistical offices and developers to use, modify, and distribute IST, while ensuring that all modifications are licenced back to SORS.
- Attribution: All derivative works and redistributions must include an attribution notice recognizing SORS as the original developer.
Contributor Licence Agreement
To manage contributions effectively, SORS plans to implement a Contributor Licence Agreement (CLA). The CLA will ensure that all contributions to IST are licenced back to SORS, allowing the organisation to maintain control over the software’s development while promoting collaboration with the wider open source community.
The key elements of the CLA include:
- Modification Rights: Contributors can modify IST for their internal use.
- No Redistribution: Contributors are not allowed to redistribute IST or its modified versions to third parties.
- No Commercial Use: IST and its derivatives cannot be used for commercial gain without explicit consent from SORS.
Conclusion
The transition of IST to an open source product represents a significant move by SORS to promote innovation and collaboration in the field of statistical data processing. While the specific licensing model for IST is still under consideration, SORS is carefully evaluating options, including the Apache licence 2.0, MIT and other permissive licence, to ensure the best balance between fostering global collaboration and protecting the integrity of the software.
By developing a flexible CLA, SORS aims to create a structured and collaborative environment where contributions from the broader statistical community, including universities, researchers, and developers, can enhance IST while ensuring its continued alignment with SORS’s goals. As the transition progresses, SORS remains committed to maintaining IST’s reputation as a modern, scalable, and secure solution for statistical data management, ensuring that it continues to meet the needs of NSOs worldwide.
Sharing OSS across communities - The Awesome List for Official Statistics Software
Statistics Netherlands
Introduction
Open source software offers significant benefits for producing official statistics, including cost savings, improved quality, greater flexibility, and the potential to foster standardisation. However, navigating the vast landscape of open source software packages already available within the statistical community can be challenging. Understanding which software exists, its maturity level, and its suitability for specific tasks is crucial for the reuse of statistical building blocks.
To address this challenge, in 2017 a number of conference participants including members of Statistics Netherlands started the awesome list of official statistics software 21. It is a community approach to facilitate knowledge sharing among statistical organisations and to promote the adoption of open source solutions. The list quickly grew from the software the initiators were involved in into an extensive catalogue of mature open source solutions in the ESS 22.
Explanation of the awesome list of statistical software
Sharing statistical software among institutes has been a valuable practice for years, particularly in areas like disclosure control, data editing, collection, and dissemination. While a few well-established solutions have been widely adopted, the current software landscape for official statistics is far more complex and dynamic than in former years. Numerous specialised packages are continually being developed, making it challenging to maintain a comprehensive overview and increasing the risk of redundant development.
To address this issue, the awesome list of official statistics software was created, inspired by the popular concept of community-driven knowledge sharing in the ‘awesome list concept’ 23. This list serves as a valuable resource for discovering and utilising generic official statistics software. The list has grown significantly since its inception, now featuring over 130 open source packages that are readily available, well-maintained, and actively used by statistical offices worldwide. It includes packages for automated access to official statistics output and is itself developed and maintained in an open source spirit.
The concept of this list is not to replicate information but as much as possible to link to the information maintained by the respective open source developer(s). Hence, each entry on the list provides a link to the software download, a brief description, and essential metadata such as the latest version, last commit, and licence. This information is automatically extracted from the packaging system metadata, ensuring consistency and ease of use.
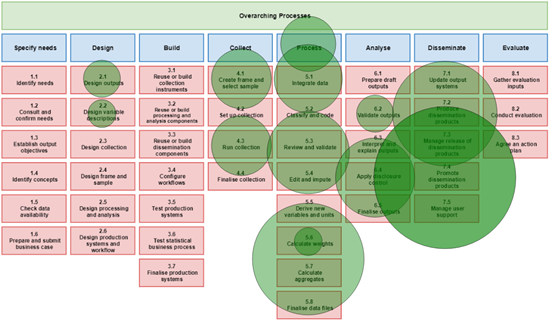
To provide users with a clear understanding of the software’s applications on the list, it is organised according to the Generic Statistical Business Process Model (GSBPM). Figure 2 illustrates the distribution of the 135 items across the various GSBPM processes.
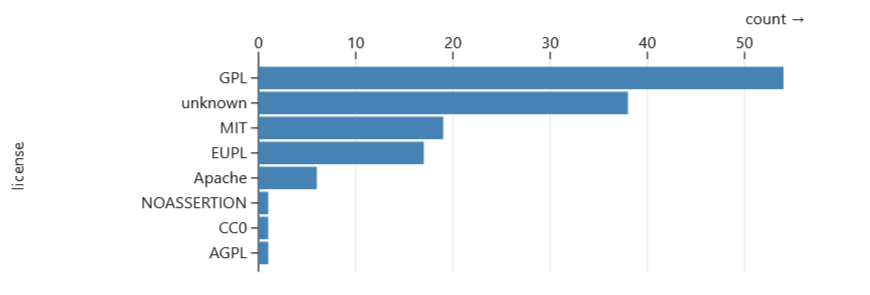
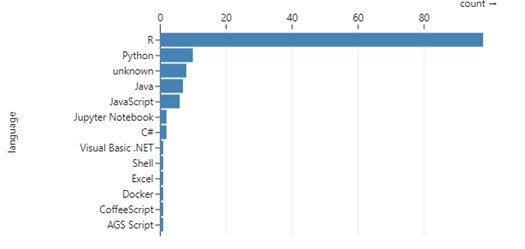
Figure 3 shows the distribution of programming languages of items on the list. The vast majority of items are written in R, which shows the excellent software sharing methods in this community. Figure 4 shows the licences used on the list. GPL is the most popular licence followed by MIT and EUPL.
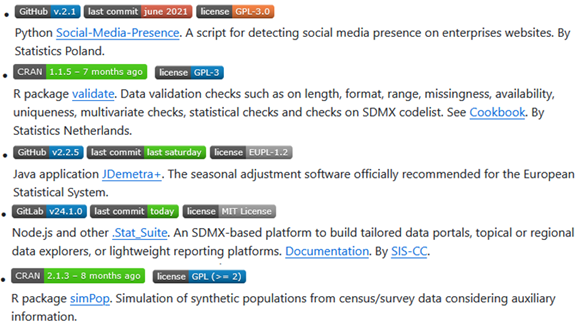
How the awesome list contributes to the FOSS in official statistics
The list has proven to be a valuable tool for sharing knowledge about existing open source solutions among different user communities in the ESS, either methodologists, statisticians, IT specialists, or management 24. Suggestions for changes or additions come from statistical organisations around the world and functionality suggestions for adding compatibility information, maturity indicators, and popularity metrics are documented on the GitHub repository itself. Concluding we can say that this list, maintained by many, has already helped software reuse among statistical organisations and as long as the community actively uses and maintains it, it will continue this important role.
sdmx.io — an open-source SDMX ecosystem
Bank for International Settlements (BIS)
Introduction
sdmx.io is an open-source ecosystem of software, guidance and learning resources dedicated to implementing the SDMX standard across the statistical lifecycle. Established under the BIS Open Tech strategy, it reflects the principle that software can be treated as a public good. Rather than a single tool, sdmx.io brings together interoperable components that cover domain modelling, data collection, processing, validation and dissemination. The initiative is meant to improve interoperability and coherence in the SDMX space and with a wide set of community-driven solutions.
Origins and purpose
The platform emerged from BIS Open Tech’s commitment to promote collaboration and reuse in the statistical and financial community. Open Tech positions software as an enabler of transparency and efficiency, encouraging institutions to contribute openly and benefit collectively. Within this framework, sdmx.io was created to curate and connect tools developed by BIS as well as by international partners — highlighting solutions that are already in use, fostering new collaborations and providing a home for resources that make adoption easier.
Partnership model
A defining feature of sdmx.io is its partnership model. The ecosystem is built collaboratively by international SDMX sponsors, national statistical offices (NSOs), central banks, private software companies and, broadly, open-source communities. Many of the tools showcased come from various organisations, ensuring that the platform reflects the breadth of innovation in the SDMX community. This diversity of contributors also guarantees that public-good components and commercially supported offerings can coexist and complement one another.
Core components
Key elements of the sdmx.io ecosystem include:
- Fusion Metadata Registry (FMR) and its Workbench for managing and editing structural metadata.
- The .Stat Suite, a community-developed statistical platform maintained by the SIS-CC consortium.
- Python toolkits such as pysdmx, gingado and LinkageX, which integrate SDMX into data science workflows.
- The SDMX Dashboard Generator, SGDS (SDMX Global Discovery Service) and SDMX TCK (Test Compatibility Kit), supporting dissemination and interoperability.
- Implementations of VTL (Validation and Transformation Language), enabling harmonised, metadata-driven processing across datasets.
These software components are accompanied by containerised environments, the SDMX Lab, workflow templates and training resources that help institutions experiment with and adopt SDMX more easily.
Distinctive qualities
What makes sdmx.io distinctive is its use-case and workflow orientation. Instead of being just a catalogue of tools, the platform promotes patterns for end-to-end statistical processes — such as using metadata registries to define structures, applying VTL transformations for validation and automating dissemination via dashboards. This practical orientation ensures that institutions can move smoothly from design to implementation, reusing established solutions rather than starting from scratch.
Governance and sustainability
The governance of sdmx.io is designed to be inclusive, with advisory groups and steering mechanisms that involve SDMX sponsors, NSOs, central banks and private sector partners. This ensures that priorities reflect real-world needs and that the ecosystem develops in a balanced, sustainable way. By combining shared ownership with clear coordination, sdmx.io provides stability while leaving room for innovation and experimentation.
Contribution to modernisation
From a modernisation perspective, sdmx.io advances transparency, interoperability and efficiency. By lowering barriers to SDMX and VTL adoption, it helps statistical institutions align with international standards. By curating open-source resources and learning materials, it fosters capacity building. And by connecting diverse partners, it creates a foundation for sustainable collaboration between public institutions and private actors. In short, sdmx.io serves as a bridge — linking technology, governance and community in support of modern statistical systems.
Conclusion
In summary, sdmx.io demonstrates how open-source collaboration can deliver practical benefits to the global statistical community. Thanks to its partnership model that spans international organisations, national authorities, private companies and open-source communities, it encourages interoperability and treating software as a public good, providing a trusted foundation for organisations seeking to modernise their statistical processes in line with international best practices.
Footnotes
Alexander Kowarik, Mark van der Loo (2018). Using R in the statistical office: the experience of statistics Netherlands and Statistics Austria. Romanian Statistical Review 1/2018 15—29↩︎
J. Pannekoek, S. Scholtus, M. van der Loo (2013). Automated and manual data editing: a view on process design and methodology. Journal of Official Statistics 29 511-537↩︎
MPJ van der Loo and E. de Jonge (2018) Statistical data cleaning with applications in R. John Wiley & Sons. ISBN: 978-1-118-89715-7↩︎
MPJ van der Loo, E de Jonge (2021). Data Validation Infrastructure for R. Journal of Statistical Software 1–22 97↩︎
MPJ van der Loo, E de Jonge (2020). Data Validation. In Wiley StatsRef: Statistics Reference Online, pages 1-7. American Cancer Society↩︎
E de Jonge E, MPJ van der Loo (2023). errorlocate: Locate Errors with Validation Rules. R package version 1.1.1, https://CRAN.R-project.org/package=errorlocate↩︎
MPJ van der Loo, E de Jonge (2021). deductive: Data Correction and Imputation Using Deductive Methods. R package version 1.0.0, https://CRAN.R-project.org/package=deductive↩︎
MPJ van der Loo (2024). Split-Apply-Combine with Dynamic Grouping. Journal of Statistical Software (Accepted for publication)↩︎
MPJ van der Loo (2022). simputation: Simple Imputation. R package version 0.2.8, https://CRAN.R-project.org/package=simputation↩︎
MPJ van der Loo (2021). Monitoring data in R with the lumberjack package. Journal of Statistical Software 98 1—11↩︎
Mark P.J. van der Loo (2021). A Method for Deriving Information from Running R Code. The R Journal 13 42–52↩︎
van der Laan, D. J. (2022). reclin2: a Toolkit for Record Linkage and Deduplication. R Journal, 14(2)↩︎
Linus’s Law: https://en.wikipedia.org/wiki/Linus%27s_law↩︎
https://www.istat.it/en/classifications-and-tools/methods-and-software-of-the-statistical-process/↩︎
https://cloud.r-project.org/web/views/OfficialStatistics.html↩︎
https://ilostat.ilo.org/resources/labour-market-information-systems/↩︎
https://github.com/SNStatComp/awesome-official-statistics-software↩︎
Olav ten Bosch, Mark van der Loo, Alexander Kowarik, (2020), The awesome list of official statistical software: 100 … and counting, The Use of R in Official Statistics - uRos202↩︎
Awesome list concept by Sindre Sorhus: https://github.com/sindresorhus/awesome↩︎
M. van der Loo, O. ten Bosch, (2023), Free and Open Source Software at Statistics Netherlands, Conference of European Statisticians, Seventy-first plenary session, Geneva, 22-23 June 2023↩︎